Niezbędne informacje wstępne
W ramach gridu dziedzinowego Complex Networks, zrealizowanego w ramach projektu PlGridNG, wspierane są trzy usługi:
- Usługa syndykacji danych - „Syndykacja” – usługa wspierająca użytkowników w zbieraniu danych z Web 2.0
- Usługa analiz danych tekstowych i sieciowych – „Analizy”
- Usługa udostępniania zbiorów danych – „Repozytorium”
Platforma AnnotationHelper jest traktowana jako część usługi syndykacji danych, która zakłada, że użytkownicy (ludzie) są częścią Internetu. Na tej zasadzie ich wiedza jest również zasobem Internetu. Zbieranie adnotacji od użytkowników Internetu również jest zbieraniem danych z Internetu.
Celem AnnotationHelper jest wsparcie naukowców z różnych dziedzin w dokonywaniu adnotacji (etykietowaniu) multimedialnych zbiorów danych (dowolna kombinacja tekstu, obrazków, muzyki i video).
Przykładowe zastosowania to: etykietowanie zdjęć pobranych z mediów społecznościowych pod kątem ich treści, etykietowanie tekstów pod kątem ich wydźwięku, emocji w nich zawartych lub emocji wzbudzających, rozpoznawanie dźwięków w pliku muzycznym lub video i inne... Etykietowanie danych jest rzeczą niezbędna m.in. w trakcie tworzenia zbioru uczącego w nadzorowanym uczeniu maszynowym (ang. supervised machine learning).
Platforma ta jest ściśle związana z „Repozytorium”, z którą wymienia dane. Z niej pobiera zbiór do przygotowania jego adnotacji, a po zakończeniu zwraca rozszerzony o adnotację zbiór z powrotem do repozytorium.
Wgranie zbioru danych do repozytorium – krok pierwszy w pracy z AnnotationHelper
Przedmiotem pracy z AnnotationHelper jest zbiór, zawierające dane do adnotacji. Mogą to być dane tekstowe, wizualne (obrazki, a dokładniej URI obrazka), dźwiękowe (URI plików dźwiękowych (MP3 albo OGG), lub url streamingu z portalu soundcloud.com), video (pliki video (MP4, OGG), lub streaming do video z portali youtube albo vimeo albo dailymotion).
Przykładowe linki:
Obraz:
https://cn.plgrid.pl/repository/image/logo_PL_Grid-NG-45px.png
{kind=link}
Muzyka:
Video:
https://youtu.be/wygy721nzRc, https://vimeo.com/6864303, http://dai.ly/x4mliz
Jak zdobyć linki z powyższych portali?
Soundcloud:
Pod wybranym utworem kliknij „Share”, potem „Embed”, skopiuj treść pola rozpoczynającego się od „<iframe”, wynij treść atrybutu src
YouTube:
Na stronie pożądanego filmu kliknij w „Udostępnij”, następnie jeszcze raz w „Udostępnij” poniżej pierwszego, skopiuj link
Vimeo:
Kliknij w „papierowy samolocik” pod ikoną serca i zegara po prawej stronie filmu. Skopiuj link z okienka, które się pojawiło.
Dailymotion:
Poniżej filmu kliknij w „Eksport” i skopiuj Permalink.
Możliwe jest wybranie dowolnej kombinacji powyższych mediów. Można poddawać adnotacji np. muzyki i tekstu, obrazu i muzyki, tekstu i video. Można również poddać adnotacji trzy i cztery z powyższych elementy na raz.
Wspierane formaty i struktury plików danych.
AnnotationHelper jest kompatybilny z dwoma formatami plików: CSV i JSON.
CSV
W przypadku wgrania do AnnotationHelper zbioru danych w formacie CSV obligatoryjny jest nagłówek, a w nim przynajmniej jedna z nazw kolumn text, img_url, music_url, video_url, przy czym wielkość znaków nie gra roli.
Kolumny te jest traktowana jako źródło danych, które mogą być poddane adnotacji.
Domyślnym separatorem jest średnik „;”, inne możliwe to: przecinek, znak tablulacji (TAB), spacja. Teksty, które w swojej treści posiadają znaki będące również separatorem (np. średnik) muszą być objęte cudzysłowami. Najlepiej, aby każdy tekst był objęty cudzysłowami.
AnnotationHelper zwróci błąd, jeśli:
- Zawartość zbioru nie jest kompatybilnym plikiem CSV
- Brak nagłówka,
- Różna liczba kolumn w poszczególnych wierszach
- Teksty zawierające znak będący separatorem nie oznaczone dodatkowymi cudzysłowami.
- Zawartość pola img_url niebędąca popranym URI
- Zbiór danych zawiera więcej niż 10000 porcji danych
- Zbiór zawiera znaki, które uniemożliwiają wczytanie go do natywnych bibliotek języka ruby. Pliki powinny być zgodne z kodowaniem UTF-8.
Przykładowy zbiór CSV:
Attr1;text;Atr3;video_url
cokolwiek;”Krótki tekst objęty cudzysłowiem ; średnik tu nic nie psuje”;cokolwiek2;http://dai.ly/x4mliz
cokolwiek3;Dwa słowa;cokolwiek4;https://vimeo.com/6864303
więcej o csv na: https://pl.wikipedia.org/wiki/CSV_%28format_pliku%29
JSON
W przypadku zbioru danych w formacie JSON zakłada się, że zbiór to tablica zawierająca obiekty, z których każdy zawiera atrybut co najmniej jeden z atrybutów: text, img_url, music_url, video_url, przy czym ostatnie trzy mogą wystąpić w jednym z dwóch miejsc w obiekcie:
- bezpośrednio jako atrybut obiektu: [ {"text": "Poddaj mnie adnotacji”, "img_url": "http://link.do.obrazka”} ]
- Jako atrybut obiektu nazwanego „other_details”, zgodnie ze schematem obowiązującym w usłudze syndykacji treści web 2.0, będącej częścią gridu Complex Networks. [ {"text": "Poddaj mnie adnotacji”, "other_details": {"img_url": "http://link.do.obrazka”}} ]
Uwagi dotyczące opisu:
- W tablicy może się znajdować maksymalnie 10000 obiektów do adnotacji
- Obiekty znajdujące się w tablicy mogą zawierać inne atrybuty. Nie zostaną one utracone w procesie adnotacji, zostaną one rozszerzone o dodatkowy atrybut zawierający wyniki adnotacji.
AnnotationHelper zwróci błąd, jeśli:
- Zawartość zbioru nie jest kompatybilnym plikiem JSON
- Złe formatowanie
- Zbiór danych zawiera więcej niż 10000 obiektów danych
- Zbiór zawiera znaki, które uniemożliwiają wczytanie go do natywnych bibliotek języka ruby. Pliki powinny być zgodne z kodowaniem UTF-8.
Przykładowy zbiór w formacie JSON:
[
{"text": "To jest przykładowy tekst", "video_url":"", "inny_atrybut": "wartość atrybutu"},
{"inny_atrybut": "wartość", "text": "To jest drugi tekst”, "video_url": "", "inny_atrybut”: "wartość atrybutu"}
]
Więcej o json na: https://pl.wikipedia.org/wiki/JSON
Zdefiniowanie nowego projektu
W zakładce „Zdefiniuj nowy projekt” dostępny jest formularz konfigurowania nowych projektów. Link do tego formularza można również znaleźć w menu AnnotationHelper po zalogowaniu.
Dokładny opis poszczególnych parametrów został zamieszczony w dalszej części tego podręcznika oraz przy tych parametrach na stronie internetowej. Aby przeczytać opis należy najechać myszą na ikonę z literką i (jak informacja), a wtedy wyświetli się chmurka (ang. tooltip).
W czasie definiowania projektu można w dowolnej chwili zapisać postęp klikając w guzik „zapisz”. W dowolnej chwili można edytować nierozpoczęty projekt wybierając go z listy dostępnej pod „Przeglądaj projekty” w menu. Aby rozpocząć badanie wciśnij „Zapisz i uruchom” z poziomu konkretnego formularza.
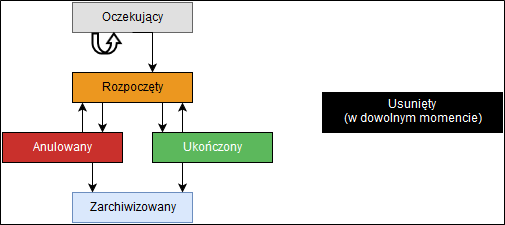
Każdy projekt w AnnotationHelper może posiadać jeden z czterech statusów: Oczekujący, Rozpoczęty, Ukończony, Anulowany. Możliwe jest jeszcze usunięcie
Statusy projektów i przyporządkowane im opcje
Każdy projekt ma w danej chwili jeden z następujących statusów:
- Oczekujący
- Rozpoczęty
- Ukończony
- Zarchiwizowany
- Anulowany
- Usunięty
Na rysunku poniżej pokazano jak projekty/badania mogę zmieniać status.
Ze względu na jego objętość podręcznik użytkownika platformy AnnotationHelper jest udostępniany w formie pliku pdf.
Podręcznik Użytkownika platformy Annotation Helper v1.2.pdf
Przykładowy case:
Przypadek użycia comedy club.docx
Zbiór danych:
Overview
Content Tools